紙に印刷された文書を画像データとして取り込み、テキストデータに変換するOCRソフト。データをWordやExcelにワンタッチで転送する機能もある。「e.Typist」は、スキャナやデジカメで取り込んだ画像ファイルや既存の画像ファイル、PDFファイルなどに含まれる文字をテキストデータ化するためのOCR(文字認識)ソフト。日本語・英語を基本に、標準で58ヵ国語に対応する。文字認識の結果、テキスト化されたデータは、プレーンテキストはもちろん、Word/Excel/PowerPointといったMicrosoft Office文書、一太郎/PDFなど、さまざまな形式に出力することが可能。
テキスト化は、
- 読み込み
- レイアウト解析
- 文字認識
- 保存
の手順で行う。メイン画面には「操作ナビ」が表示され、手順ごとに操作をガイドしてくれる。4段階の手順を連続で自動実行させることも可能で、「どの手順までを自動実行にするか」の設定もできる(例えば、文字認識までで自動実行を停止し、それ以降は手動で行う、など)。さらに、WordやExcelへの転送・保存の自動実行も可能だ。認識言語は「日本語」「英語」「日本語(欧文混在)」に加え、欧米、アジアの各国語を指定できる。出力時には、元画像のレイアウトを保持したままの出力を指定できるほか、段組や改行コード/空白の挿入方法などの指定も行える。
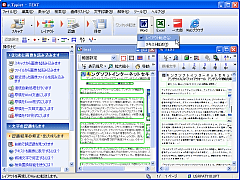
認識結果の確認・修正は、元画像と認識テキストを左右または上下に並べ、シンクロ表示させて行える。元画像と認識結果のテキストを同一画面上にオーバーレイ表示する機能もある。
紙原稿からの画像取り込みをデジカメで行った場合の、画像補整機能も備えている。デジカメ写真が長方形や樽型になってしまったときの補整や、色合い/手ぶれの補整を行うことで、デジカメ写真からの文字認識精度を高められる。